
How AI Works.
A Brief (kind of) and Sketchy (definitely) Introduction to Artificial Intelligence

Before we get started, let’s talk about expectations. Yours as a reader and mine as a writer. My goal here is to help people better understand Artificial Intelligence (AI) so that they are better informed and can help their professions, communities, and society use the technology for good and not evil (more on that later). To do that, I’m going to be drawing on my work, reading, and experience in AI. Clearly, I am not the only person on the internet doing this. If you read these posts you’ll find links and references to them. To help you better understand AI, I’m going to over simplify things. A lot. This is intentional. So if you’re also someone who works with AI reading this and you think I’m leaving out some critical details, you may be right. If you’d like to talk about that, contact me. If you’d like to dress me down in the comments, I’d rather you not.
What is AI?
It’s not artificial and it's not intelligent. AI is predictions. An AI system is a whole lot of data that has been trained, controlled by an algorithm, and does a specific thing. When you ask AI to do anything, to draft an email, remove an object from a photograph, or explain organic chemistry to you like you were a six year old, AI is predicting what it thinks you want. Those predictions are powered by, and limited by, the quality and quantity of the training data and the effectiveness of the algorithm. Before we get to Large Language Models (LLM) like Claude or ChatGPT, let's start small to better understand them.
AI You Likely Use Everyday
Predictive search in Google is a good example of a specific AI system. When you start a search in Google, their AI will predict what you are looking for based on their data. The more people who search for the same thing, the greater the chance Google will predict it to you. Because it is a prediction, it is sometimes useful and correct, and sometimes it isn’t.
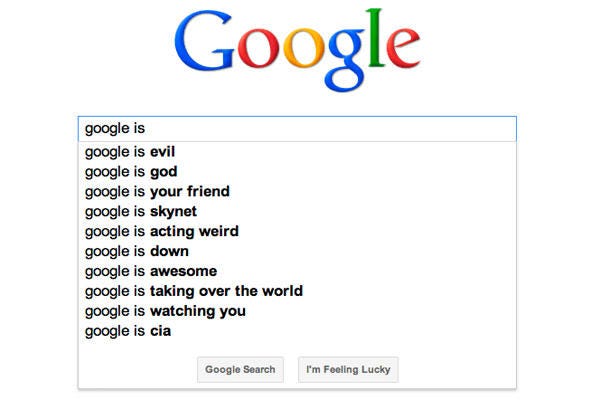
Image: A screenshot of predictive search in Google.
Speech to text on your phone is another example of AI predictions. When the AI “hears” your specific combinations of consonants and vowels spoken in your language, it will predict what you meant by typing it on your screen. Which is why sometimes it is right, and sometimes it is spectacularly wrong. I often use speech to text in Google Docs. If I say the name of the famous (in my field at least) educational theorist Robert Gagné, Voice Typing will write Robert Kanye. And if you understand that AI is predictions, this makes perfect sense. There are a lot more people saying Kanye than Gagné. There is a lot more data for Kanye than Gagné. So when I say that combination of consonants and vowels in English to Voice Typing in Google Docs, the logical prediction would be Kanye. So it is a prediction, but it isn’t what I want. That is AI in a nutshell: it is an educated guess at what you want.
AI systems are dynamic and constantly evolving, hopefully for the better (more on that later). So if a lot more people started saying Gagné than were saying Kanye, Voice Typing would use Gagné when it “hears” those consonants and vowels together. Candidly, I doubt that will happen.
Every AI system is predicting what it thinks you want. In order to predict, it needs training data to compare your prompt in an AI system. And it needs an algorithm to tell it how to use that training data. If you want the AI system to create a picture of a penguin playing a Fender Telecaster at the South Pole, the system has to be trained well enough to know what a penguin is, what shape a Telecaster is, and what the South Pole looks like, and it needs a procedure to put it all together.
Let’s Build an AI
Let’s say we want to create an AI that will allow us to use our phone’s camera to identify dog breeds. Our AI is going to need two things: training data and algorithms.
Training data is all of the samples we use that would tell us what a different dog looks like. So, pictures of German Shepherds, Beagles, etc.
The algorithm is the set of instructions the AI will be given to make use of the training data, such as “is the ear pointed or floppy?”
Training Data
First, we’d need to know how many breeds of dogs there are. This is a tricky question, because there is disagreement about this. The number of recognized dog breeds depends on the organization or kennel club doing the recognition:
American Kennel Club (AKC): Recognizes 200 breeds (as of January 2025).
Federation Cynologique Internationale (FCI): Recognizes 360 breeds, as it is a worldwide organization.
United Kennel Club (UKC): Recognizes 300+ breeds.
But let’s go with the AKC and 200 breeds. To train the AI, you’d need a lot of pictures of every breed of dogs. And you’d need 360 degree photos of dogs so that you could identify them from multiple angles. If we use Labrador Retrievers as an example, you’d need pictures of Black Labs, Yellow Labs, Chocolate Labs, etc. And all of these photos would need to be clearly labeled in a way that the AI system can use, perhaps by the shape of the ear or the type of fur. At the moment, a lot of that labeling and data preparation is done by humans, but more on that later. While the actual number of images you would need to train the AI system would vary based on a number of factors, a baseline number would be 1,000 images per breed. The more breeds you have in your AI, the more images you would need of each breed so that the AI could make fine distinctions, such as the difference between a Greyhound and a Whippet. (Greyhounds are larger, so you know.)

Image: A Whippet and a Greyhound. (https://thelifeofnello.com/italian-greyhound-vs-whippet)
For an AI to make that type of distinction, you might need 10,000 images per breed, and all of them would need to be labeled correctly. Let’s call it somewhere between 200,000 and 2,000,000 images.I think the technical definition of how many images you would need is a “big ol’ truck load.” Or, simply, a lot.
Algorithms
Generally speaking, algorithms are a set of steps that are used in any process. So a recipe is an algorithm. A set of directions to travel from point A to point B is an algorithm. In an AI system, an algorithm is the process used to make sense of the training data. So if we have a big ol’ truck load of carefully labeled pictures of 200 different breeds of dogs, the algorithm helps sort them out in some way to make a final decision, or prediction. The AI may use sorting strategies, such as fur type, shape of the ears, body size, etc. to help make an identification, or a prediction, of what type of dog it is. What might that look like? Here’s an incredibly stripped down summary of an algorithm that might do that.
Simple Algorithm Summary
Input: Dog pictures with labels (e.g., "Labrador," "Poodle," “Golden Retriever”).
Processing: The AI analyzes the pictures through layers of sorting tools to learn patterns like fur type, ear shape, and body size.
Output: The AI guesses, or predicts, the breed of a new picture.
The AI doesn't "know" what a dog is like humans do—it just learns to recognize patterns (e.g., shapes, colors) from the examples we give it. And, the more high-quality, diverse pictures we provide, the better the sorting strategies (algorithm) get at recognizing the breeds. Simple, right?
Bias in Training Data and Algorithms
Bias in training data and algorithms will impact the output of any AI system. Biases may be explicit, done intentionally, or implicit, done without our realizing we have a bias. Which is to say a bias in AI training data and algorithms doesn’t have to be intentional to be a bias. A bias simply skews the prediction one way or another..
AI systems that we use, like ChatGPT, Gemini, Claude, etc. were largely trained on publicly available internet (mostly, but more on that later) on the western Internet, largely focused on Western Europe and the United States. That bias often shows up when we ask it to create images. For example, every time I ask ChatGPT to create an image of a “boss,” it creates a picture of a white man. Again, that bias may not be intentional, but it is pretty clear. Below is the image that was created when I wrote this post.

Image: ChatGPT’s image of a boss.
What does this bias mean? This means that the idea of a “boss” in the data was likely trained towards one gender (male) and one ethnicity (white). Why? I don’t know, but my guess is that it was an implicit bias of the people preparing the training data, or that the training data had more white men bosses than other genders and ethnicities. They had an idea of what a “boss” looked like, and this was it. I would also say that this output for boss has been consistent for as long as I’ve been using ChatGPT. I did this exercise in a classroom less than a week before I posted this, and every image was of a white man, though most of them had a beard. Someone described them as “wanna be Property Brothers.” I thought that was pretty funny. But the bias is deeper than race and gender, it is a class bias as well. Look at the office. It is a corner office in an urban high rise. You can see the skyscrapers behind him. This isn’t the boss of a grocery store, or the boss of a machine shop. This is a C-suite boss, perhaps much like the boss of a larger tech firm that made the AI.
Of course, a bias can be malicious or benign, and I’m not suggesting either, but it does exist. The image bias in ChatGPT can be controlled with a prompt. You can ask it to create an image of a boss that is not a white man. I did, and I got this:

Image: ChatGPT picture of a boss that is not a white man.
The gender bias is gone, but many of the other biases remain. Again, we can control that, perhaps, with a prompt, but understanding that bias can skew an output can help you better use AI systems.
All AI systems have biases in them. Sometimes that bias is intentional and understandable. For example, I chose to use AKC’s list of breeds in my example rather than one of the others. So my AI would leave out 100 - 160 different breeds. That’s an explicit bias, perhaps one that I can even defend, but not a malicious one, or one that is particularly high-stakes. The AI system I describe for identifying breeds of dogs is not a high stakes AI system. If the system guesses, or predicts wrong, we might be frustrated or amused, but we’re not harmed.
At the moment, most companies use AI systems to evaluate resumes, deciding who gets invited to an interview and who doesn’t. If an AI algorithm is written that puts greater value on an Ivy League degree over other degrees, that’s a bias (we could argue intentional or implicit) with a high-stakes outcome (we could argue malicious intent), that determines who gets a job and who doesn’t. It values one class of people over all others. It decides who gets an interview and who doesn’t.
There are many AI systems in place now that are high stakes, like a military defense AI system that distinguishes enemy aircraft from civilian ones. Or an AI facial recognition system used to allow people on airplanes that works better on one group of people than another. In systems like these, biases in the data and algorithms have real world, high-stakes consequences if they predict wrong. And most AI systems will predict wrong at some point. As we look at a society that uses more and more AI systems for more and more high stakes decisions, this is something we must pay a lot more attention to. We have to be able to trust the builders of AI that they can:
Not be biased or at least;
Identify their biases, explicit and implicit, and control for them;
Use high quality training data that is impeccably prepared;
Test their systems rigorously before using them in high stakes environments;
Employ strategies to manage inaccurate output.
Final Thoughts
At the moment, there are no meaningful regulations or guard rails in place for AI in the United States. Whether or not we need them is a matter of some debate. AI enthusiasts, and AI companies, insist that regulations will stifle innovation and potentially leave the US at a competitive disadvantage on the world stage. Others feel like we need some guidelines or regulations to help us manage how AI is used and to give the public confidence that AI systems are safe and we can trust them in high stakes applications. I can see both sides of that coin, though I think I lean significantly to the “guardrails” arguments if not the “regulations” argument.
In future posts I’ll be examining other issues related to AI and expanding on ideas here. But hopefully this will give you a better idea about what AI, and what AI is not.
Marshall, thanks for sending this. I found it very interesting and helpful. Looking forward to reading more of your posts.
This is a very interesting article on AI. Thanks for sharing! I didn’t know companies used AI to decide who gets an interview for a job, and I’m not sure I love the idea. Just like the example you showed with the picture of the boss, it relies on stereotypes. I’m new to AI and love exploring it, but I don’t like the idea of companies using it to make important decisions, such as determining the best fit for a job.